有栈协程和无栈协程
协程coroutine(或称纤程fiber)是用户级线程,由应用程序而非系统内核控制线程调度和上下文切换,是非抢占的、主动让出CPU资源的多线程。和内核级线程thread相比,用户级线程优点在于内存占用小、切换成本低、能大量创建,如果配合非阻塞API能够处理大规模并发,缺点是没法发挥多核的性能、一个时刻一个CPU上只有一个协程,但是可以通在内核级线程中使用协程间接发挥多核性能。
协程的实现分为有栈协程(stackful)和无栈协程(stackless)两种。有栈协程指每个协程会保存单独的上下文(执行栈、寄存器等),协程的唤醒和挂起就是拷贝、切换上下文;无栈协程指单个线程内所有协程都共享同一个执行栈,协程的切换就是简单的函数返回。
| 有栈协程 | 无栈协程 | 备注 | |
| 例子 | lua thread | C# yield return
C# async\await |
|
| 是否拥有单独的上下文 | 是 | 上下文包括寄存器、栈帧 | |
| 局部变量保存位置 | 栈 | 堆 | 无栈协程的局部变量保存在堆上,比如generator的数据成员 |
| 优点 | 1. 每个协程有单独的上下文,可以在任意的嵌套函数中任何地方挂起此协程
2. 不需要编译器做语法支持,通过汇编指令即可实现 |
1. 不需要为每个协程保存单独的上下文,内存占用低
2. 切换成本低,性能更高 |
|
| 缺点 | 1. 需要提前分配一定大小的堆内存保存每个协程上下文,所以会出现内存浪费或者栈溢出
2. 上下文拷贝和切换成本高,性能低于无栈协程 |
1. 需要编译器提供语义支持,比如C# yield return语法糖
2. 只能在这个生成器内挂起此协程,无法在嵌套函数中挂起此协程 3. 关键字有一定传染性,异步代码必须都有对应的关键字。作为对比,有栈协程只需要做对应的函数调用 |
无栈协程无法在嵌套函数中挂起此协程,有栈协程由于是通过保存和切换上下文包括寄存器和执行栈实现,可以在协程函数的嵌套函数内部yield这个协程并唤醒 |
说明一下关于无栈协程无法嵌套挂起协程的问题。有栈协程可以理解为不同的上下文(寄存器和执行栈等),而函数调用就是修改寄存器和操作执行栈,嵌套函数的调用还是在同一个上下文即协程中,所以能够在任意的嵌套函数中挂起和唤醒当前的协程(即保存现场和恢复现场)。而无栈协程是通过编译器将生成器改写为对应的迭代器类型(内部实现是一个状态机),只有在生成器内部的yield return会被作为一个单独的状态机状态。
有栈协程在嵌套函数中挂起:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
void coroFunc() { int a = 10; foo(a); a = 20; foo(b); } void foo(int val) { if(a == 10) { print(val); yield(); // 挂起协程 } print(val); } |
无栈协程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
IEnumerator Wait5Sec() { Console.WriteLine("Wait for 5 sec"); yield return new WaitForSecondsTest(5); } IEnumerator Speak() { int i = -1; while (true) { Console.WriteLine(++i); //Wait5Sec(); // 这样无法挂起,只是会返回一个IEnumerator类型 yield return Wait5Sec(); // 可以挂起,但挂起的位置并不是Wait5Sec里面的yield,也就是不会打印"Wait for 5 sec" } } |
有栈协程的优点在易用性上,通常只需要调用对应的方法,就可以切换上下文挂起协程,而无栈协程需要在编译器将代码编译为对应的状态机代码,挂起的位置在编译器确定。
无栈协程的优点在性能上,不需要保存单独的上下文,内存占用低,切换成本低,性能高。缺点是需要编译器提供语义支持,比如C#的async\await语法糖,由编译器生成对应的代码。
有栈协程的实现可以通过汇编代码手动拷贝寄存器和栈数据,或者用ucontext.h函数簇。
无栈协程的实现是通过编译器对语法糖做支持,比如C#的yield return, aysnc\await,编译器将带有这些关键字的方法编译为生成器,以及对应的类型作为状态机。
单从实现上看,有栈协程更接近于内核级线程,都需要为每个线程保存单独的上下文(寄存器、栈等),区别在于有栈协程的调度由应用程序自行实现,对内核是透明的,而内核级线程的调度由系统内核完成,是抢占式的。内核级线程通过系统调用(syscall)在内核中创建,由内核维护所有线程的调度,由于调度是抢占式的,所以一个线程阻塞,不会导致整个进程阻塞。而用户级线程由于是有应用程序非抢占式调度,一个协程阻塞会导致整个进程(或者说主线程)阻塞。
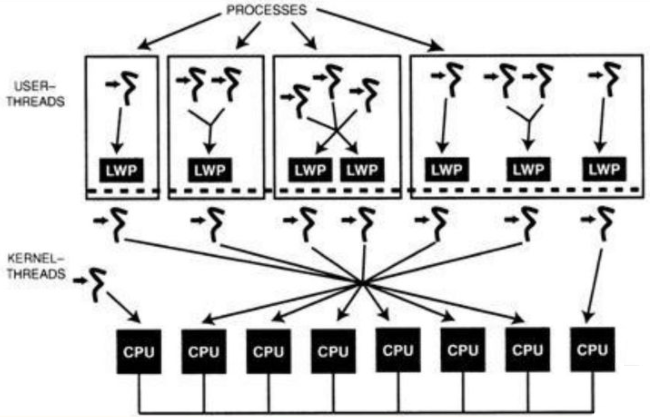
协程、线程和CPU的关系
用户级线程 -> 内核级线程 -> CPU
内核线程是内核中实际获得CPU资源并执行的单位。用户线程想要跑必须被调度和某个内核线程绑定,然后内核线程再去竞争CPU资源。默认情况下,每个进程都有一个主线程执行main函数。用户级线程、内核级线程、CPU有一对一、多对一、多对多三种模型。